LEFT OUTER JOIN
왼쪽 테이블의 모든 값이 출력되는 조인

RIGHT OUTER JOIN
오른쪽 테이블의 모든 값이 출력되는 조인

UNION
두 개의 SQL 실행 결과를 결합하는데 사용함. 중복 데이터가 있을 경우 제거!
[SQL 1]
UNION
[SQL 2];
- 열 개수가 같아야 하고, 열 이름이 같아야 하고, 각 열의 데이터 타입이 동일해야함.
ex)
SELECT name, age FROM students WHERE age < 30
UNION
SELECT name, age FROM students WHERE age < 32;
UNION ALL
두 개의 SQL 실행 결과를 결합하는데 사용함. 중복 데이터가 있어도 전부 출력!
[SQL 1]
UNION ALL
[SQL 2];
ex)
SELECT name, age FROM students WHERE age < 30
UNION ALL
SELECT name, age FROM students WHERE age < 32;
서브 쿼리
하나의 SQL문 안에 포함되어 있는 또 다른 SQL문.
ex) 나이가 30세 미만인 학생의 이름, 나이, 그리고 모든 학생들의 평균 나이를 조회
SELECT
name,
age,
(SELECT AVG(age) FROM students) AS avg_age
FROM students
WHERE age < 30
FROM 절에서 사용하는 서브 쿼리
ex) 데이터베이스, 알고리즘 수강 정보를 조회하는 SQL 문
SELECT *
FROM
(
SELECT name, class_name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
)FROM절의 서브 쿼리의 경우 서브 쿼리의 결과를 마치 가상의 테이블처럼 사용할 수 있음.
WHERE 절에서 사용하는 서브 쿼리
ex) 데이터베이스, 알고리즘을 수강하는 학생의 이름, 나이, 주소를 조회하는 SQL 문
SELECT name, age, address
FROM students
WHERE name IN (
SELECT name
FROM classes
WHERE class_name IN ('데이터베이스', '알고리즘')
)
- 서브 쿼리에서 classes 테이블에서 데이터베이스, 알고리즘을 수강하는 학생의 이름을 조회함.
- students 테이블에서 서브 쿼리에서 조회한 이름만 필터링하여 결과로 보여줌.
DDL
Data Definition Language의 약자. 데이터를 정의하는 언어

CREATE
데이터베이스 생성
CREATE DATABASE [데이터베이스명]
테이블 생성
ex) 학생 정보를 저장할 테이블을 생성하는 SQL문
CREATE TABLE test_db.students (
name VARCHAR(255) NOT NULL,
age INT NOT NULL,
address VARCHAR(255) NOT NULL
)

테이블 제약조건(Constraint)
테이블에 부적절한 데이터가 입력되는 것을 방지하기 위해 테이블 생성 시점에 규칙을 정해놓는 것.
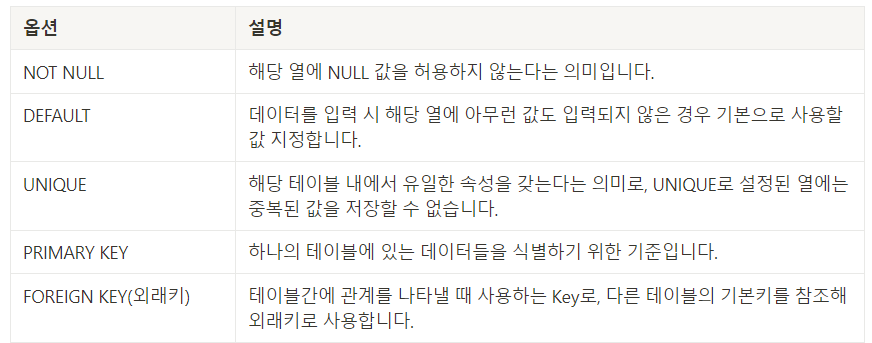
CREATE 실습)
CREATE TABLE data_test (
id VARCHAR(10) PRIMARY KEY,
create_data DATE DEFAULT now(),
data_time TIMESTAMP DEFAULT now()
);
INSERT INTO data_test (id) VALUES (45);
select id, create_data, to_char(data_time, 'YYYY-MM-DD HH:MI:SS') as DATE
from data_test;
FOREIGN KET (외래키)
테이블간에 관계를 나타낼 때 사용하는 key. 다른 테이블의 기본키를 참조해 외래키로 사용함.
즉, 한 테이블의 외래키는 연결되어 있는 다른 테이블의 기본키 중 하나.

CREATE TABLE customer (
id INT PRIMARY KEY,
name VARCHAR(10) NOT NULL,
address VARCHAR(200),
contact VARCHAR(100)
);
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
date TIMESTAMP DEFAULT now(),
payment VARCHAR(50),
amount INT,
delivery_amount INT,
FOREIGN KEY (customer_id) REFERENCES customer(id)
)
+) 실무에서는 의미적으로 fk를 사용한다? (= fk를 잘 사용하지 않는다.) 읽어보기
외래키를 사용하는 이유는 데이터의 정합성을 유지하기 위해서 사용을 하는데요.
하지만 실무에서는 수작업으로 데이터를 다루는(수정, 생성) 경우가 빈번합니다. 이때 테이블의 관계상 데이터 생성 순서가 맞지 않으면 에러가 발생하기도 하고, 어쩔 수 없이(e.x, 데이터 재생성을 위한 등) 데이터(자식 테이블)를 삭제 하는 경우 CASCADE 옵션이 걸려 있다면 부모 테이블 데이터가 삭제가 되는 참사가 발생하기도 합니다.
문제가 생겨 빠르게 수작업을 처리를 해야 되는 경우에 외래키로 인해서 처리가 늦어질 수도 있고, 작업을 처리하는 개발자의 번거로움이 있습니다.
외래키가 걸려 있는 테이블을 다룰 때 수작업 시 번거로움으로 인해서 외래키를 사용하지 않는 경우가 많습니다 :)
또 다른 이유로는 데이터베이스 설계를 초기에 잘 해놓았더라도 시간이 지나면서 추가 개발과 설계가 수정이 되어 질 수 있습니다. 데이터 정합성을 유지하기 위한 외래키가 이후에는 더 큰 수정 개발을 불러 일으킬 수도 있겠습니다. 외래키를 만들 때는 득과 실을 잘 따져보고 걸어야 되지만 제 경우에는 실제 실무(Spring boot 및 오라클, MY-SQL 기반)에서는 아직까지는 외래키를 생성하는 경우를 본 적이 없습니다. - 출처 인프런 MJ코딩
외래키 설정시에는 두가지 옵션이 있음
1. RESTRICT
대부분의 DBMS 시스템에서는 DEFAULT 설정으로 RESTRICT이 적용됨. 외래키 제약조건이 설정된 경우 참조된 행이 삭제되는 것을 방지하여 데이터 일관성을 유지함.
자식 테이블의 행이 부모 테이블의 행을 참조하지 않는 상태가 되어야 부모 테이블의 해당 레코드 삭제 가능!
2. CASCADE
부모 테이블의 행이 삭제되면 관련된 자식 테이블의 행도 자동 삭제됨.
자동 삭제가 되기 때문에 의도치 않은 삭제를 주의해야함.
Daily Quiz
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
1. 문제에 나온 PRODUCT 테이블과 OFFLINE_SALE 테이블을 생성해주세요
CREATE TABLE product (
product_id INT NOT NULL,
product_code VARCHAR(8) NOT NULL,
price INT NOT NULL
);
CREATE TABLE offline_sale (
offline_sale_id INT NOT NULL,
product_id INT NOT NULL,
sales_amount INT NOT NULL,
sales_data DATE DEFAULT now()
);
INSERT INTO product (product_id, product_code, price) VALUES (1, 'A1000011', 15000);
INSERT INTO product (product_id, product_code, price) VALUES (2, 'A1000045', 8000);
INSERT INTO product (product_id, product_code, price) VALUES (3, 'C3000002', 42000);
INSERT INTO offline_sale (offline_sale_id, product_id, sales_amount, sales_data) VALUES (1, 1, 2, '2022-02-21');
INSERT INTO offline_sale (offline_sale_id, product_id, sales_amount, sales_data) VALUES (2, 1, 2, '2022-03-02');
INSERT INTO offline_sale (offline_sale_id, product_id, sales_amount, sales_data) VALUES (3, 3, 3, '2022-05-01');
INSERT INTO offline_sale (offline_sale_id, product_id, sales_amount, sales_data) VALUES (4, 2, 1, '2022-05-24');
INSERT INTO offline_sale (offline_sale_id, product_id, sales_amount, sales_data) VALUES (5, 1, 2, '2022-07-14');
INSERT INTO offline_sale (offline_sale_id, product_id, sales_amount, sales_data) VALUES (6, 2, 1, '2022-09-22');
2. PRODUCT 테이블과 OFFLINE_SALE 테이블간에 PRODUCT_ID 기준으로 교집합 row를 출력해주세요
SELECT product_id FROM product
UNION
SELECT product_id FROM offline_sale;'Back-End > DBMS' 카테고리의 다른 글
| [DBMS] 데이터 모델링 (0) | 2024.03.22 |
|---|---|
| [DBMS] ALTER/DB Index/DCL/정규화 (1) | 2024.02.27 |
| [DBMS] DML/내장함수/그룹화, 정렬/JOIN 기본 (2) | 2024.02.22 |
| [DBMS] 데이터베이스와 SQL (0) | 2024.02.21 |